
The task
One of the features that we were to develop for our customer was the following:
Provide a solution for embedding Open Graph tags in order to coherently present links to products / other content in one of the main social media platforms.
This could have an overall impact on how the application would be perceived as a whole — think about all those shares, private messages that contain neat, clickable widgets with description.

What are Open Graph tags?
Open tags are basically html meta tags that describe how your URL links should be displayed on social media platforms. They can consist of many properties, but the simplified (and fully functional) OG tags may look like this:
<meta property="og:title" content="The Rock" />
<meta property="og:type" content="video.movie" />
<meta property="og:url" content="https://www.imdb.com/title/tt0117500/" />
<meta property="og:image" content="https://ia.media-imdb.com/images/rock.jpg"/>This should be placed in the
of your html document. An exhaustive specification can be found here.Tech Stack
There are a few things worth mentioning about our stack. The application was developed with the following technologies: Flask on the Backend (DDD, Event Sourcing and all the other bells and whistles that cool kids use nowadays), Vue on the Frontend (SPA application — it turns out that it will be crucial later), everything is hosted on AWS (a myriad of 2- and 3-letter service name abbreviations, you know the drill).
The following things are vital to the whole picture:
- We use the AWS CloudFront (CDN)
- We have a Single Page Application on the Frontend
Let's find out why this is so important.
The struggle:
Rich Hickey, the inventor of Clojure, once said:
You know they say economists know the price of everything and the value of nothing? Well, programmers know the benefits of everything and the trade-offs of nothing.
So what was the nothing in our case? Well, it was the SPA application. Of course, we all know the benefits of SPA:
- They look & feel like a native application
- They can be deployed really easily (Vercel, Amazon S3, just to name a few)
- They will usually be faster than classic server-side rendering due to lower bandwidth usage
What is the trade-off of SPA? They are extremely bad at SEO, including in our case, which was the OG tag generation. The problem lies deep in the essence of the SPA application since there are – at the and of the day – three files: index.html, some .css and a .js bundle.
The main purpose of the index.html is script execution. To present any meaningful data, JavaScript must be executed.
Web crawlers used by companies such as Twitter (twitterbot) or Facebook (facebook external hit) do not execute javaScript at all. In some basic cases, libraries such as react/vue helmet can come to the rescue. In simple terms, they inject some data (such as og:tags) in the
tag, but here we refer just to static content. Generating OG tags per product seems to be unreachable this way.The solution:
The first thing that came to mind was to use Server Side Rendering. At the dawn of meta-frameworks, such as Sevelte Kit or Nuxt, this seemed feasible in the greenfield project, but in our case, we had a working (not so straightforward) piece of software! This would commit a lot of resources (financial and personal) to rewrite an entire FE application just for the sake of one feature.
We decided to leverage lambda@edge — a tiny serverless javaScript function that "sits" on the CDN edge and is executed when some certain rules are met (for example, the url matches). This way, lambda manages the requests.
The idea was simple. If a "real person" requests content, we serve it as usual (serve cached content or pass the request on to the origin), but when known web crawlers request content, we serve them a small, regular html file with no JS attached, but instead with dynamically generated OG tags, as if it were rendered server-side. How to find out whether it's our customer requesting some product details, or just a bot hitting our application? There are many ways, but the simplest one is to decide who is who, based on the user-agent.
Bots that search for OG tags are widely known (Facebot, Twitterbot, to name just a few). You can find most of them in the following repository. To put it simply, if a requestor has an http user-agent header set to some well-known value for web crawlers, we consider it a web-crawler, and dynamically built html is served; otherwise, a single-page application is loaded. Below, you can find a sketch of the presented solution:
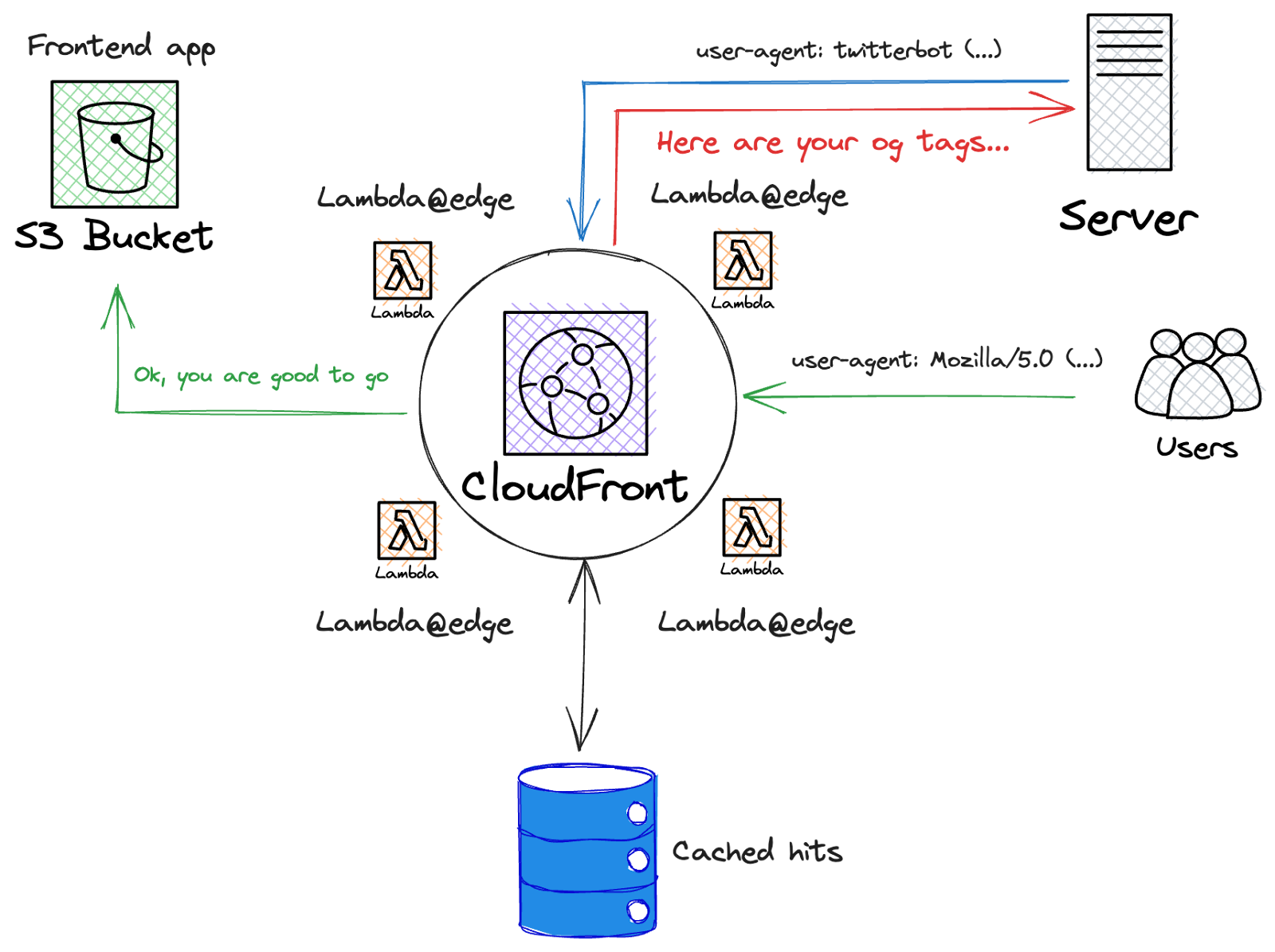
Lambda@Edge
Ok, we have our infrastructure cleared, but now — where to deploy our logic? This is where Lambda@edge comes to the rescue.
Lambda@Edge is an AWS service that runs your code in response to an event generated by Amazon CloudFront (CDN). Basically, there are four types of such events (look at the diagram below):

- After CloudFront receives a request from a viewer (viewer request)
- Before CloudFront forwards the request to the origin (origin request)
- After CloudFront receives the response from the origin (origin response)
- Before CloudFront forwards the response to the viewer (viewer response)
In our solution, we decided to use a viewer request event. It is worth mentioning that lambda@edge is limited to node.js and python runtimes. What is more, it does not support env variables (this can be overcome, for example by fetching env variables from the origin server by subscribing to Origin Response), but this is out of the scope of this article.
Talk is cheap, show me the code
Every lambda@Edge function should implement some async function that has the following signature:
exports.handler = async (event, context, callback) => {};When lambda runs, our event object is passed to the handler. The context object contains data related to the cloudFront itself and callback can be used for non-asynchronous code. A detailed description of these objects can be found in AWS lambda docs. In our case, we are interested in intercepting the (viewer) request:
exports.handler = async (event, context, callback) => {
const request = event.Records[0].cf.requst;
};Next, we want to check whether the request was made by the bot or by our customer. If the request was made by the customer, we simply pass the request:
exports.handler = async (event, context, callback) => {
const request = event.Records[0].cf.requst;
if (!isUserAgentBot(request)) {
callback(null, request);
return;
}
};Our isUserAgentBot function simply checks the 'user-agent' header:
const BOT_LIST = [...]
const isUserAgentBot = (request) => {
let userAgent = request.headers['user-agent'][0].value;
if (!userAgent) {
return false;
}
return userAgent in BOT_LIST;
};
exports.handler = (event, context, callback) => {
const request = event.Records[0].cf.requst;
if (!isUserAgentBot(request)) {
callback(null, request);
return;
}
};The next step is the extraction of the product id from the request's uri. We will need this id to query our api for product details. If the product cannot be extracted, we pass the request back to the application. If everything is fine, we fetch product data that will be used to build og tags.
const fetch = require('node-fetch');
const API_URL = 'https://our-api.com'
const BOT_LIST = [...]
const isUserAgentBot = (request) => {
let userAgent = request.headers['user-agent'][0].value;
if (!userAgent) {
return false;
}
return userAgent in BOT_LIST;
};
const getProductIdFromUrl = (url) => {
return url.split('/')[2];
};
async function fetchProductData(host_from_req, product_id) {
const url = `${API_URL}some/og/url/${product_id}/`;
let result = await fetch(url, {headers: {ORIGIN: host_from_req}});
const data = await result.json();
return data;
};
exports.handler = async (event, context, callback) => {
const request = event.Records[0].cf.requst;
if (!isUserAgentBot(request)) {
callback(null, request);
return;
}
const productId = getProductIdFromUrl(request.uri);
if (!productId) {
callback(null, request);
return;
}
const host = `https://${request.headers["host"][0].value}`;
const productDetails = await fetchProductData(host, productId);
};The final step will be to prepare an html doc with og tags and serve it in a response (this is a full example):
const fetch = require("node-fetch");
const API_URL = "https://our-api.com";
const BOT_LIST = [...];
const isUserAgentBot = (request) => {
let userAgent = request.headers["user-agent"][0].value;
if (!userAgent) {
return false;
}
return userAgent in BOT_LIST;
};
const getProductIdFromUrl = (url) => {
return url.split("/")[2];
};
async function fetchProductData(host_from_req, product_id) {
const url = `${API_URL}some/og/url/${product_id}/`;
let result = await fetch(url, { headers: { ORIGIN: host_from_req } });
const data = await result.json();
return data;
}
exports.handler = async (event, context, callback) => {
const request = event.Records[0].cf.requst;
if (!isUserAgentBot(request)) {
callback(null, request);
return;
}
const productId = getProductIdFromUrl(request.uri);
if (!productId) {
callback(null, request);
return;
}
const host = `https://${request.headers["host"][0].value}`;
const productDetails = await fetchProductData(host, productId);
let html = `
<!doctype html>
<html lang="en">
<head>
<meta charset="UTF-8"/>
<title>Document</title>
</head>
<body></body>
</html>
`;
html = html.replace(
"</head>",
`<meta property="og:type" content="website">
<meta property="og:url" content="${host}/product/${productId}">
<meta property="og:title" content="${productDetails.product_name}">
<meta property="og:description" content="${productDetails.description}">
<meta property="og:image" content="${productDetails.image}">
</head>`,
);
const response = {
status: 200,
statusDescription: "OK",
headers: {
"content-type": [
{
key: "Content-Type",
value: "text/html",
},
],
},
body: html,
};
callback(null, response);
};Please note that in a production grade code, you will need to deal with a bunch of other things, for instance handling error codes (what should happen when our API fails), behaviors per path pattern in the CloudFront service, and so on, but anyway, this is a good place to start :)
Summary
To sum up, CDN (CloudFront) and Lambda@Edge can be used to enhance the behaviour of our main application. In our case, it was used for search engine optimization, but the possibilities are endless, such as serving different content to different countries, attaching some specific headers to the responses, and so on.
